
情報処理学会第81回全国大会中高生ポスターセッション発表
コンピュータは漢詩を作ることができるのか?
神戸大学附属中等教育学校 能丸天志くん(5年生)

コンピュータが漢詩を詠むことは可能か ~漢詩自動生成プログラムの作成~
本研究は、漢詩を機械学習アルゴリズムを用いて自動生成することを目的としました。
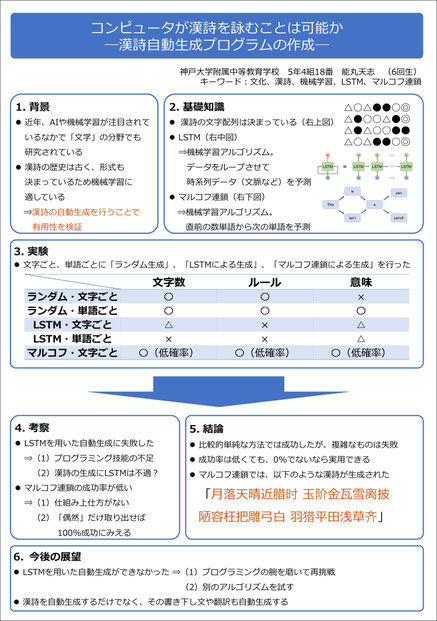
今回の研究では、文字ごとと単語ごとに機械学習アルゴリズムは一切使わずに、漢詩のルールに合うように、ランダムにそれらを当てはめて生成する「ランダム生成」、LSTMと呼ばれるアルゴリズムを用いた「LSTMによる生成」、マルコフ連鎖と呼ばれるアルゴリズムを用いた「マルコフ連鎖による生成」の3種類、計5種類(マルコフ連鎖による生成は文字ごとのみで実施)の検証をしました。
結果は、文字ごとのランダム生成では、意味のない漢字の羅列が生成されました。LSTMによる生成では、どちらも漢詩のルールを学習できませんでした。一方、単語ごとのランダム生成とマルコフ連鎖による生成では、意味の取れそうなものは出力されたものの、それが本当に意味をもち、詩的に良いものかについては議論の余地があります。
また、マルコフ連鎖による生成については、漢詩のルールに合ったものが生成されることはあまり多くなかったものの、成功率が0%でなかったため、うまくいったものだけを取り出せば実用化はできるのではないかと考えました。そこで、このシステムを採用したTwitterBot「李白くん(@rihaku_markov)」を作成しました。李白くんは、今後もアップデートを行っていく予定です。
※クリックすると拡大します
■研究を始めた理由や経緯は?
この研究を始めたきっかけとして、学校での国語の授業があります。ある授業で、「漢詩(七言絶句)を自分で作る」といった内容があり、そこで漢詩にはルールがあり、それに合うように単語を当てはめていくと漢詩ができるということを知りました。単語をルールに合うように配置するだけで漢詩ができるなら、コンピュータにも漢詩を作ることが可能なのではないかと考えたことが、この研究を始めたそもそものきっかけです。
■かかった時間はどのくらい?
研究を始めてから、発表まで10か月程度です。
■今回の研究で苦労したことは?
LSTMを実装する際にKerasというライブラリを用いましたが、それでも複雑で、サンプルプログラムなども参考にしたものの、実装に時間がかかったことです。他にも、TwitterBotを製作するのが初めてだったため、李白くんを作る際にも苦労しました。
■「ココは工夫した!」「ココを見てほしい」という点は?
李白くんには、今回最も成功したといえる単語ごとのマルコフ連鎖を用いました。この仕組みの問題点として、ルールに合った漢詩が必ずしも生成されないことと、元データの漢詩とかなり類似したものが生成されることが多いことが挙げられます。そのため、李白くんでは、生成された漢詩を、まずルールに適合しているかを確認し、その上で元の漢詩との類似度を確認し、類似度が一定値を下回っているものだけを採用し、投稿することでこの問題を回避できるよう工夫しました。
なお、類似度の計算には、Pythonの標準ライブラリを用いました。
■今回のポスター発表の感想をどうぞ!
今回のポスター発表は、学校内でのポスター発表とは異なり、情報学の専門家の先生方の前で発表することができ、中には手厳しいものあったが的確なご指導を賜ることができたり、自分よりも優れた同世代の人と多く会って刺激を受けたりすることができたので、とても有意義なものになったと思います。また、聴衆は少ない人数であるとはいえ、何度も発表することができて、人前で話すいい練習になったと思います。
今回の経験を生かして、大学受験や大学での学び・研究だけでなく、社会に出てからも頑張っていきたいと思います。